1. Task Modeling & Graph Definition
First, we give the definition of Simple Task and Complex Long-horizon Task:
- Simple Task (\(T\)): A primitive manipulation unit defined as \( T = \langle o_t, o_{s_1}, o_{s_2}, s_\text{init}, s_\text{goal} \rangle \), where \( o_t \in \mathcal{O} \) is the target manipulable object, \( s_\text{init}=s_\text{init}(o_t,o_{s_1}) \) defines the initial condition, and \( s_\text{goal}=s_\text{goal}(o_t,o_{s_2}) \) defines the success criteria.
- Complex Long-horizon Task (\(\mathcal{T}\)): An ordered sequence of simple tasks \( \mathcal{T} = \{T_1, T_2, ..., T_K\} \) with \( K\ge2 \).
To accomplish these tasks, an Action Flow \( \pi(T) \) is executed to achieve a specific simple task, while an Action Transfer \( e(T_k,T_{k+1}) \) bridges consecutive simple tasks \( T_k \) and \( T_{k+1} \) by aligning their boundary world states.
Building upon these concepts, we formalize the task space as a structured Affordance-Graphed Task World. The world is represented as a universal directed graph \( \mathcal{G} = (V, E) \):
- Nodes (\(V\)): Defined by the triplet \( V = \mathcal{O} \times \mathcal{A} \times \mathbb{N}^+ \), where \( \mathcal{O} \) is the set of manipulable objects (aligning with \( o_t \) in simple tasks), \( \mathcal{A} \) is the set of atomic actions, and \( \mathbb{N}^+ \) denotes the discrete temporal dimension.
- Edges (\(E\)): Represent the dynamic state transitions in the world, strictly corresponding to the Action Flows (intra-task execution) and Action Transfers (inter-task transitions) defined above.
2. Compositional Reachability Theorem
Based on our probabilistic graph model, we provide a theoretical guarantee for the solvability of generated tasks:
Proposition: Let \( S_\tau \subset \mathcal{S} \) denote the global world state at time \( \tau \). Assume the
AGT-World graph \( G_{S_0} \subset \mathcal{G} \) satisfies:
- Primitive Completeness: For any simple task \( T=\langle o_t,o_{s_1},o_{s_2},s_\text{init},s_\text{goal}\rangle, s_\text{init},s_\text{goal}\in \mathcal{S} \), there exists an action flow \( \pi(T)\subset V_{S_0} \text{ s.t. } \mathbb{P}(s_\text{goal} \mid s_\text{init},\pi) > 0 \);
- Connectivity of Context: For any two consecutive simple tasks \( T_k, T_{k+1} \), if their boundary conditions align (i.e., \( S_\text{goal}^{(k)} \approx S_\text{init}^{(k+1)} \)), there exists an action transfer \( e_k(o_t^{(k)},o_t^{(k+1)}) \subset V_{S_0} \) connecting them with a positive probability \( \mathbb{P}\left(S_\text{init}^{(k+1)} = S_\text{goal}^{(k)+} \mid S_\text{goal}^{(k)},e_k\right) > 0 \).
Then for any complex long-horizon task \( \mathcal{T}=\{T_k\}_{k=1}^{K} \) and global world state \( S_0=S_\text{init}^{(1)}, S_\tau=S_\text{goal}^{(K)}\subset \mathcal{S} \), there exists
\[
\begin{split}
&\Pi=\{\pi_k\subset V_{S_0}: \pi_k\sim p_\text{F}(\pi\mid \mathcal{T};\epsilon_1)\}_{k=1}^K,\\
&\mathcal{E}=\{e_k\subset V_{S_0}: e_k\sim p_\text{T}(e\mid \mathcal{T};\epsilon_2)\}_{k=1}^{K-1},
\end{split}
\]
such that
\[
\mathbb{P}\left(S_\tau\mid S_0,\Pi,\mathcal{E}\right)=\prod_{k=1}^{K}\underbrace{\mathbb{P}(S_{\tau_k}\mid S_{\tau_{k-1}}^+,\pi_k)}_{\text{Execution Feasibility}}\cdot\prod_{k=1}^{K-1}\underbrace{\mathbb{P}(S_{\tau_k}^+\mid S_{\tau_{k}},e_k)}_{\text{Transition Consistency}}>0
\]
with \( [0,\tau]=\bigcup_{k=1}^K[\tau_{k-1},\tau_{k}] \).
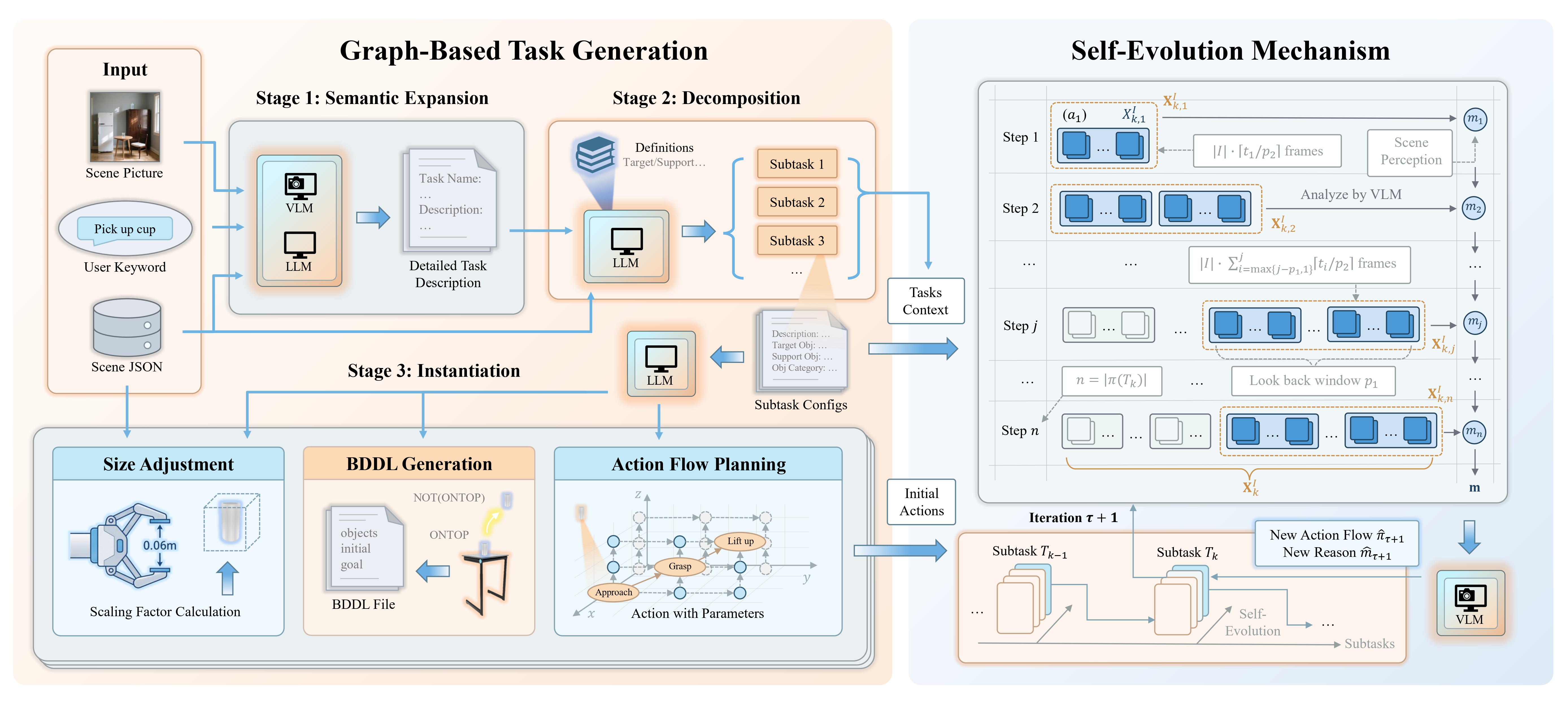
3. Self-Evolution Mechanism (Expression 17)
To refine execution parameters autonomously, the evolution from iteration \( \tau \) to \( \tau+1 \) is governed by the following mechanism:
\[ (\hat{\pi}_{\tau+1}, \hat{m}_{\tau+1}) \sim p_E\left((\pi, m) \mid \mathbf{X}_k^I, \mathbf{m}, \mathcal{T}, \left\{\left(\hat{\pi}_i, \hat{m}_i\right)\right\}_{i=1}^{\tau}; \epsilon_4\right). \]
Symbols Explanation:
- \( \hat{\pi}_{\tau+1} \): The action flow for the \((\tau+1)\)-th iteration.
- \( \hat{m}_{\tau+1} \): The semantic critique generated by the VLM for the \((\tau+1)\)-th iteration.
- \( \mathbf{X}_k^I \): Multi-view visual feedback (Subset of \(\{\text{Global}, \text{Overhead}, \text{Wrist}\}\)) for the \(k\)-th subtask.
- \( \mathbf{m} \): Step-wise semantic critique generated by the VLM.
- \( \{ (\hat{\pi}_i, \hat{m}_i) \}_{i=0}^\tau \): Historical execution memory including previous failed attempts and reasoning.